
Big Data works on the 4V principle that is Volume, Velocity, Variety, and Veracity. It is a vast topic that does not have one specific definition. It varies with the reference and the objective of the speaker. Scientifically and Technically- Data that has large volumes generated by a variety of sources at a great velocity that authenticates with the veracity of the source is called Big Data. Big data can be structured, semi-structured, or unstructured which is dependent on the source. Data can be generated every day on the web in various forms like- web, texts, images, videos, social media posts, reactions, comments, likes, etc. These are large data sets that are required to be processed with parallel processing.
Let’s look into the principles of Big Data in detail:
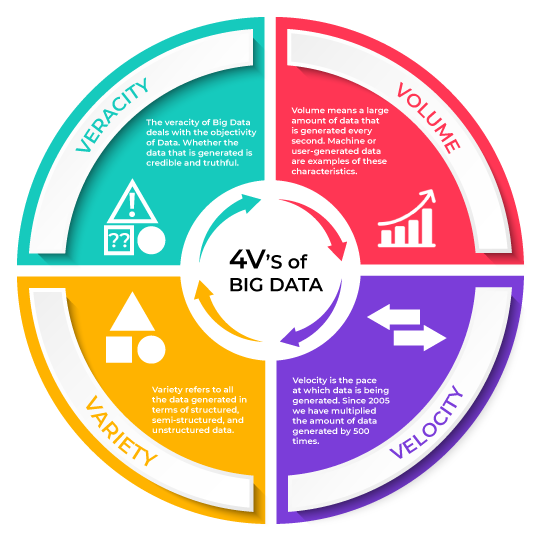
Volume-
Volume means a large amount of data that is generated every second. Machine or user-generated data are examples of these characteristics. As the computer evolves data is also evolving with a 10x speed: gigabytes to petabytes and zettabytes.
Velocity-
Velocity is the pace at which data is being generated. Since 2005 we have multiplied the amount of data generated by 500 times. 64.2 zettabytes of data is generated by 2020. Over the next five years, we are expected to grow this number by180 zettabytes. [1]
Variety-
Variety refers to all the data generated in terms of structured, semi-structured, and unstructured data. It can be generated either by humans or machines. The most commonly added data are structured data such as texts, tweets, pictures, and videos. Written text, audio recordings, are part of unstructured data.
Veracity-
The veracity of Big Data deals with the objectivity of data. Whether the data that is generated is credible and truthful. It is one of the most important V of Big Data which also determines the truthfulness of decision making. At times data is fetched from multiple data sets under different instances, which leads to the homogeneity of data. It also makes it almost impossible to trace the source of this data. This homogeneity of data makes attained data, Questionable? It may also result in faulty decisions. Therefore, data that can be traced back to the source and confirm authenticity is used in critical decision-making.
Challenges and Opportunities in Big Data
There are approximately 1.7 billion [2] web pages that are currently live and 800 million [3] of them are currently giving out information about Big Data.
It is imperative to think that Big Data is going to be the next big thing. Big Data comes with an immense number of opportunities in Health, Education, Automobile, Transportation and Research, etc. To deal with large amounts of data with a traditional approach is inconsistent. To understand why we must observe challenges related to Big Data.
Challenges with Big Data-
Data Acquisition and Collection-
Big data does not generate out of a vacuum, it has to be recorded from a data generating source. One important aspect is to define the filter so that they may not censor important information. A major part of the data that is generated, is of no Use. Therefore it is required to filter [4] out at the time of collection. Defining filters to save only useful datasets is an expensive yet extremely difficult task. The second big data challenge is recording metadata that defines how the data has been generated. It is extremely important to minimize the human burden from recording data by the acquisition of metadata acquisition systems. Data provenance is equally important because the data that is generated has to be recorded from the source and defined at the source data pipeline. This process is important to characterize the truthfulness of data.
Big Data Variety-
Due to data being generated from multiple sources heterogeneity remains a big concern for Big Data. User-generated data from different sources with massive users increases the complexity of obtained data. The tweets, Instagram pictures, discussion videos, groups, etc. are some of the examples which may concern heterogeneity.
Transactional data is generated due to multiple transactions. These transactions are undergoing every second with different modes of payments. These are further linked with different products or services being purchased/ rented/ or granted at one time. It becomes an extremely challenging task to identify and dissect it from its source and merge it with the data pipeline.
Scientific data that is generated with complex physical experiments and observations recorded with the changes from matter physics to biological sciences of genome studies to celestial data comes to extreme complexities. It requires extreme attention to formulate observation with distinct sources and maintain consistency.
Big Data Integration and Cleaning-
Since the data that is recorded is heterogeneous, it is not enough to merely record it and throw it into a repository. Data analysis is challenging and complex, it's more than locating, identifying, and understanding data.
All of this is required to happen in an automated manner due to time and labour constraints for effective large-scale data analysis. To counter this indifference the semantics are introduced in a form that is understandable by the computer so that it can be resolved robotically. It requires an enormous amount of work at the data integration stage to attain error-free resolution.
Human Collaboration-
There are numerous patterns that humans can understand and relate to. The machines to some extent are not able to develop a human understanding. It is despite thorough computational algorithms derived from real-world experiences. Therefore, analytics of big data cannot be designed as completely computational.
It requires human intervention [5] and continuously requires a human in the loop to formulate patterns and decisions. In today's world, it often requires multiple experts from different domains to understand the outcome of computationally analysed data.
It becomes extremely expensive to gather a bunch of experts from different domains to gain insight into data. Therefore it becomes extremely important for data scientists and experts to work in a distributed system. It requires the data and findings to be completely discreet and available for open scrutiny by these experts. A popular new source of obtaining results is called crowdsourcing.
Conclusion -
Big Data is a nascent technology and it has the potential to grow through leaps and bounds. The micromanagement feature of this technology makes this extremely affordable and convenient. Big Data is a game-changer. Many organizations are using a more analytical approach to decision-making. A small change in Company's decision-making can save those lots of money. Therefore every option to increase the efficiency of the system is valuable. It is the best time to dive deeper into the concepts of Big Data and build a rich career with edifypath by opting for a course.

©️ 2024 Edify Educational Services Pvt. Ltd. All rights reserved. | The logos used are the trademarks of respective universities and institutions.